Beyond One Shot, Beyond One Perspective: Cross-View and Long-Horizon Distillation for Better LiDAR Representations
- 1Nanjing University of Aeronautics and Astronautics
- 2National University of Singapore
- 3Zhejiang University
- 4Nanjing University of Posts and Telecommunications
- 5SKL-TI


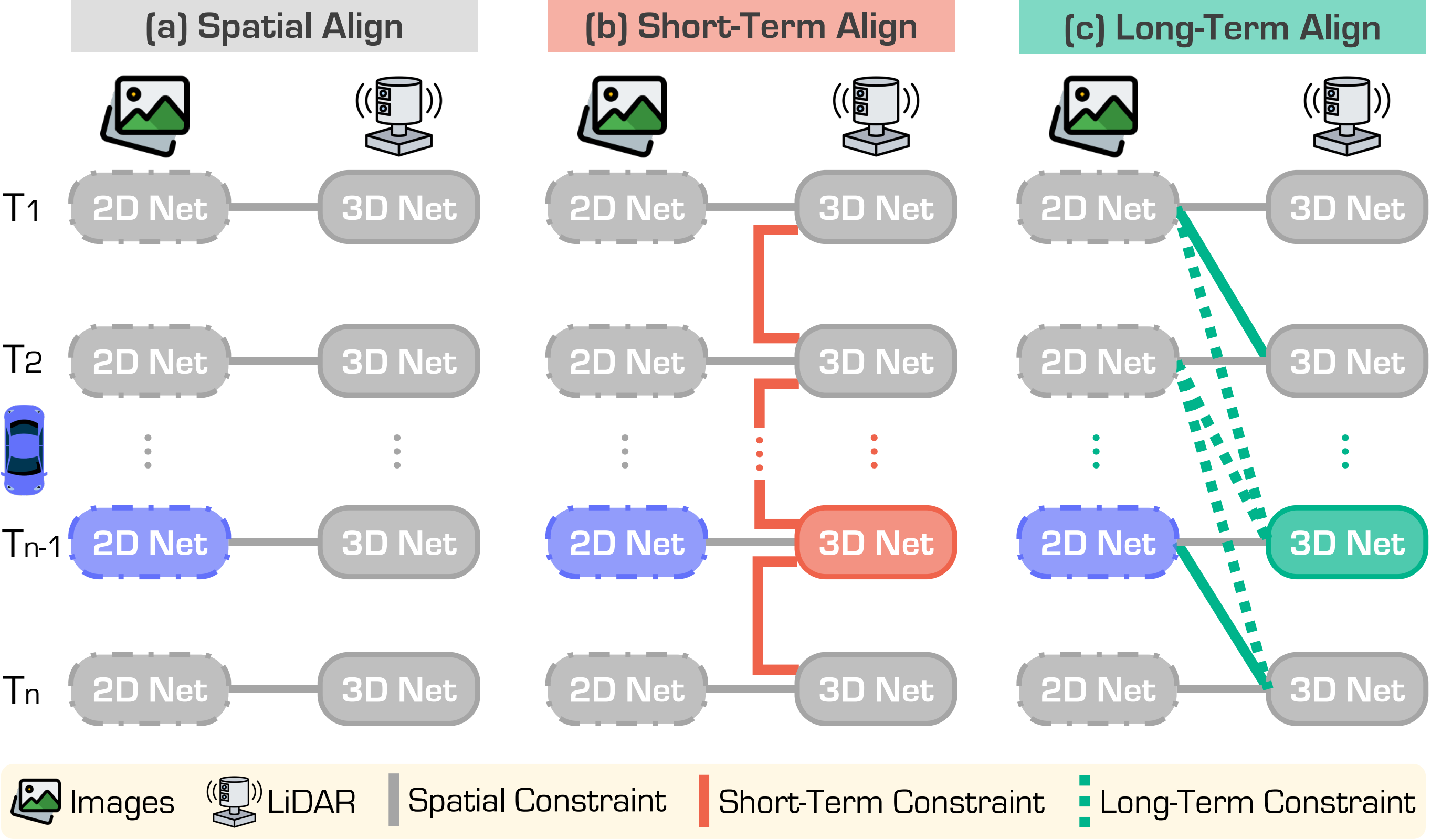 Figure 1. Illustrative examples of image-to-LiDAR pretraining paradigms.
(a) Spatial Alignment aligns LiDAR features with corresponding image features in the spatial domain without considering temporal consistency.
(b) Short-Term methods propagate LiDAR features frame by frame, ensuring feature consistency across neighboring frames but fail to capture long-term dependencies.
(c) Our approach leverages Long-Term image sequences to enrich LiDAR representations, enabling a more comprehensive understanding of long-range dependencies and motion patterns.
Figure 1. Illustrative examples of image-to-LiDAR pretraining paradigms.
(a) Spatial Alignment aligns LiDAR features with corresponding image features in the spatial domain without considering temporal consistency.
(b) Short-Term methods propagate LiDAR features frame by frame, ensuring feature consistency across neighboring frames but fail to capture long-term dependencies.
(c) Our approach leverages Long-Term image sequences to enrich LiDAR representations, enabling a more comprehensive understanding of long-range dependencies and motion patterns.
In this work, we present LiMA, a simple yet effective framework that distills rich motion patterns from longer sequences into LiDAR representations, enhancing the robustness and generalizability in LiDAR data pretraining. LiMA comprises three key components: (1) Cross-View Aggregation, which unifies multi-view image features to construct a high-quality memory bank; (2) Long-Term Feature Propagation, which enforces temporal consistency module, which enforces temporal consistency and propagates long-term motion cues; and (3) Cross-Sequence Memory Alignment, which improves robustness by aligning long-term features across diverse driving contexts.
By integrating these three components, LiMA effectively captures both spatial and temporal correlations within and across driving sequences. Our framework ensures high pretraining efficiency with an increased number of frames, requiring no more than 20 hours for pretraining. Furthermore, LiMA introduces no additional computational overhead during downstream tasks, ensuring efficient deployment.
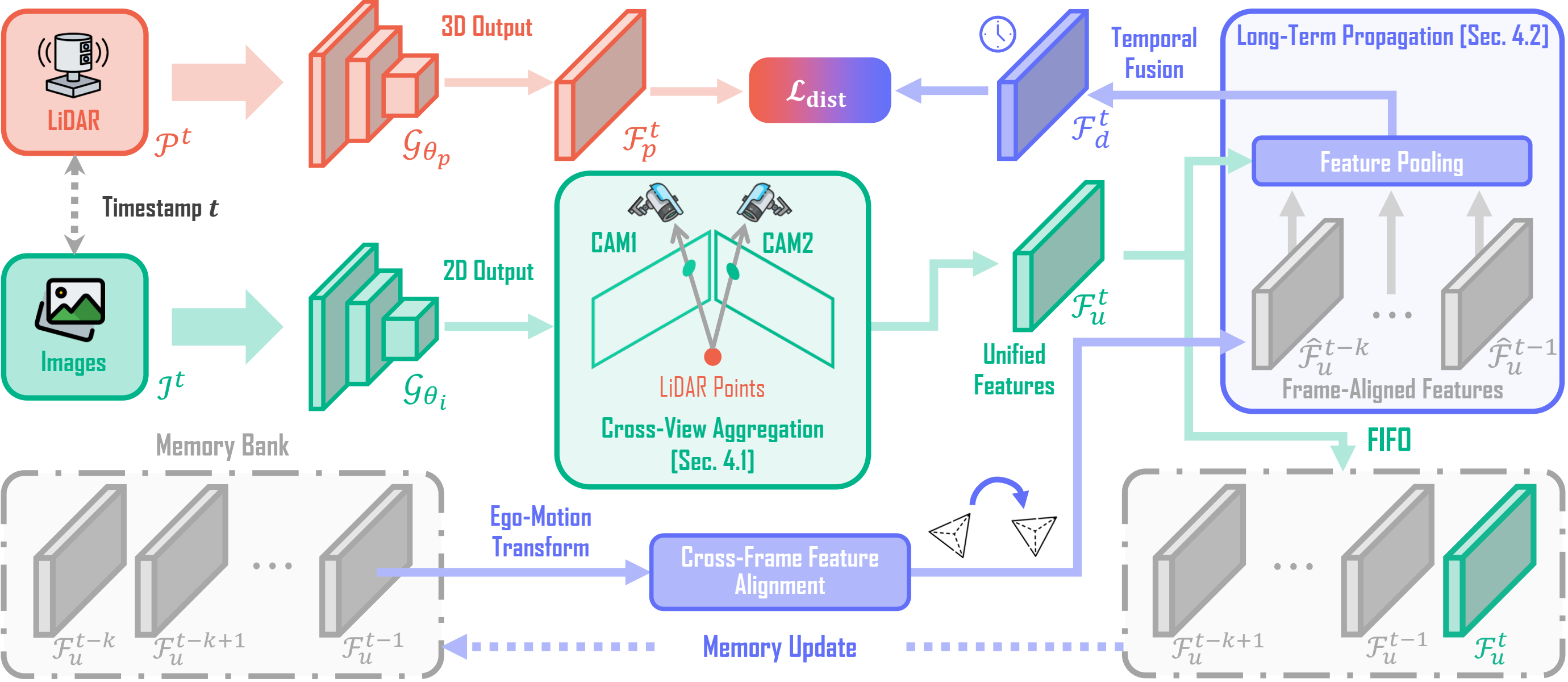 Figure 2. Overview of the LiMA framework. At each timestamp t, multi-view image features are first extracted and unified through the Cross-View Aggregation module.
A Memory Bank is introduced to maintain unified image features from the past k frames, enabling temporal feature propagation and fusion to capture Long-Term Motion Patterns.
The enriched temporal features are distilled into LiDAR representation, enabling Cross-Modal Learning.
The memory bank is continuously updated in a first-in, first-out (FIFO) manner, ensuring effective feature propagation and refinement for future frames.
Figure 2. Overview of the LiMA framework. At each timestamp t, multi-view image features are first extracted and unified through the Cross-View Aggregation module.
A Memory Bank is introduced to maintain unified image features from the past k frames, enabling temporal feature propagation and fusion to capture Long-Term Motion Patterns.
The enriched temporal features are distilled into LiDAR representation, enabling Cross-Modal Learning.
The memory bank is continuously updated in a first-in, first-out (FIFO) manner, ensuring effective feature propagation and refinement for future frames.
 Figure 3. Cosine similarity between a query point (marked as the red dot) and: (1) image features, and (2) LiDAR point features projected onto the image. Colors range from red (indicating high similarity) to blue (indicating low similarity). Best viewed in colors.
Figure 3. Cosine similarity between a query point (marked as the red dot) and: (1) image features, and (2) LiDAR point features projected onto the image. Colors range from red (indicating high similarity) to blue (indicating low similarity). Best viewed in colors.
Table 1. Comparisons of state-of-the-art LiDAR pretraining methods pretrained on nuScenes and fine-tuned on nuScenes, SemanticKITTI, and Waymo Open datasets, respectively, with specific data portions. LP denotes linear probing with frozen backbones. All scores are given in percentage (%).
| Method | Venue | Backbone (2D) | Backbone (3D) | Frames | nuScenes | KITTI | Waymo | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LP | 1% | 5% | 10% | 25% | Full | 1% | 1% | |||||
| Random | - | - | - | - | 8.10 | 30.30 | 47.84 | 56.15 | 65.48 | 74.66 | 39.50 | 39.41 |
| SLidR | CVPR'22 | ResNet-50 | MinkUNet-34 | 1 | 38.80 | 38.30 | 52.49 | 59.84 | 66.91 | 74.79 | 44.60 | 47.12 |
| ST-SLidR | CVPR'23 | ResNet-50 | MinkUNet-34 | 1 | 40.48 | 40.75 | 54.69 | 60.75 | 67.70 | 75.14 | 44.72 | 44.93 |
| TriCC | CVPR'23 | ResNet-50 | MinkUNet-34 | 2 | 38.00 | 41.20 | 54.10 | 60.40 | 67.60 | 75.60 | 45.90 | - |
| Seal | NeurIPS'23 | ResNet-50 | MinkUNet-34 | 2 | 44.95 | 45.84 | 55.64 | 62.97 | 68.41 | 75.60 | 46.63 | 49.34 |
| CSC | CVPR'24 | ResNet-50 | MinkUNet-34 | 1 | 46.00 | 47.00 | 57.00 | 63.30 | 68.60 | 75.70 | 47.20 | - |
| HVDistill | IJCV'24 | ResNet-50 | MinkUNet-34 | 1 | 39.50 | 42.70 | 56.60 | 62.90 | 69.30 | 76.60 | 49.70 | - |
| SLidR | CVPR'22 | ViT-S | MinkUNet-34 | 1 | 44.70 | 41.16 | 53.65 | 61.47 | 66.71 | 74.20 | 44.67 | 47.57 |
| Seal | NeurIPS'23 | ViT-S | MinkUNet-34 | 2 | 45.16 | 44.27 | 55.13 | 62.46 | 67.64 | 75.58 | 46.51 | 48.67 |
| SuperFlow | ECCV'24 | ViT-S | MinkUNet-34 | 3 | 46.44 | 47.81 | 59.44 | 64.47 | 69.20 | 76.54 | 47.97 | 49.94 |
| ScaLR | CVPR'24 | ViT-S | MinkUNet-34 | 1 | 49.66 | 45.89 | 56.52 | 61.07 | 65.79 | 73.39 | 46.06 | 47.67 |
| LiMA | Ours | ViT-S | MinkUNet-34 | 6 | 54.76 | 48.75 | 60.83 | 65.41 | 69.31 | 76.94 | 49.28 | 50.23 |
| SLidR | CVPR'22 | ViT-B | MinkUNet-34 | 1 | 45.35 | 41.64 | 55.83 | 62.68 | 67.61 | 74.98 | 45.50 | 48.32 |
| Seal | NeurIPS'23 | ViT-B | MinkUNet-34 | 2 | 46.59 | 45.98 | 57.15 | 62.79 | 68.18 | 75.41 | 47.24 | 48.91 |
| SuperFlow | ECCV'24 | ViT-B | MinkUNet-34 | 3 | 47.66 | 48.09 | 59.66 | 64.52 | 69.79 | 76.57 | 48.40 | 50.20 |
| ScaLR | CVPR'24 | ViT-B | MinkUNet-34 | 1 | 51.90 | 48.90 | 57.69 | 62.88 | 66.85 | 74.15 | 47.77 | 49.38 |
| LiMA | Ours | ViT-B | MinkUNet-34 | 6 | 56.65 | 51.29 | 61.11 | 65.62 | 70.43 | 76.91 | 50.44 | 51.35 |
| SLidR | CVPR'22 | ViT-L | MinkUNet-34 | 1 | 45.70 | 42.77 | 57.45 | 63.20 | 68.13 | 75.51 | 47.01 | 48.60 |
| Seal | NeurIPS'23 | ViT-L | MinkUNet-34 | 2 | 46.81 | 46.27 | 58.14 | 63.27 | 68.67 | 75.66 | 47.55 | 50.02 |
| SuperFlow | ECCV'24 | ViT-L | MinkUNet-34 | 3 | 48.01 | 49.95 | 60.72 | 65.09 | 70.01 | 77.19 | 49.07 | 50.67 |
| ScaLR | CVPR'24 | ViT-L | MinkUNet-34 | 1 | 51.77 | 49.13 | 58.36 | 62.75 | 66.80 | 74.16 | 48.64 | 49.72 |
| LiMA | Ours | ViT-L | MinkUNet-34 | 6 | 56.67 | 53.22 | 62.46 | 66.00 | 70.59 | 77.23 | 52.29 | 51.19 |
Table 2. Domain generalization study of different LiDAR pretraining methods pretrained on the nuScenes dataset and fine-tuned on a collection of seven different semantic segmentation datasets, respectively, with specific data portions. All scores are given in percentage (%).
| Method | Venue | ScriKITTI | Rellis-3D | SemPOSS | SemSTF | SynLiDAR | DAPS-3D | Synth4D | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1% | 10% | 1% | 10% | Half | Full | Half | Full | 1% | 10% | Half | Full | 1% | 10% | ||
| Random | - | 23.81 | 47.60 | 38.46 | 53.60 | 46.26 | 54.12 | 48.03 | 48.15 | 19.89 | 44.74 | 74.32 | 79.38 | 20.22 | 66.87 |
| SLidR | CVPR'22 | 39.60 | 50.45 | 49.75 | 54.57 | 51.56 | 55.36 | 52.01 | 54.35 | 42.05 | 47.84 | 81.00 | 85.40 | 63.10 | 62.67 |
| Seal | NeurIPS'23 | 40.64 | 52.77 | 51.09 | 55.03 | 53.26 | 56.89 | 53.46 | 55.36 | 43.58 | 49.26 | 81.88 | 85.90 | 64.50 | 66.96 |
| SuperFlow | ECCV'24 | 42.70 | 54.00 | 52.83 | 55.71 | 54.41 | 57.33 | 54.72 | 56.57 | 44.85 | 51.38 | 82.43 | 86.21 | 65.31 | 69.43 |
| ScaLR | CVPR'24 | 40.64 | 52.39 | 52.53 | 55.57 | 53.65 | 56.86 | 54.06 | 55.96 | 44.42 | 51.96 | 81.92 | 85.58 | 64.36 | 67.44 |
| LiMA | Ours | 45.90 | 55.13 | 55.62 | 57.15 | 55.05 | 57.81 | 55.45 | 56.70 | 46.66 | 52.32 | 83.11 | 86.63 | 66.04 | 70.19 |
Table 3. Comparisons of state-of-the-art LiDAR pretraining methods pretrained and fine-tuned on the nuScenes dataset with specific data portions. All detection methods employ CenterPoint or SECOND as the 3D object detection backbone.
| Method | Venue | nuScenes | |||||
|---|---|---|---|---|---|---|---|
| 5% | 10% | 20% | |||||
| mAP | NDS | mAP | NDS | mAP | NDS | Backbone: VoxelNet + CenterPoint | |
| Random | - | 38.0 | 44.3 | 46.9 | 55.5 | 50.2 | 59.7 |
| PointContrast | ECCV'20 | 39.8 | 45.1 | 47.7 | 56.0 | - | - |
| GCC-3D | ICCV'21 | 41.1 | 46.8 | 48.4 | 56.7 | - | - |
| SLidR | CVPR'22 | 43.3 | 52.4 | 47.5 | 56.8 | 50.4 | 59.9 |
| TriCC | CVPR'23 | 44.6 | 54.4 | 48.9 | 58.1 | 50.9 | 60.3 |
| CSC | CVPR'24 | 45.3 | 54.2 | 49.3 | 58.3 | 51.9 | 61.3 |
| ScaLR | CVPR'24 | 44.3 | 53.3 | 48.2 | 57.1 | 50.7 | 60.8 |
| LiMA | Ours | 46.5 | 56.4 | 50.1 | 59.6 | 52.3 | 62.3 | Backbone: VoxelNet + SECOND |
| Random | - | 35.8 | 45.9 | 39.0 | 51.2 | 43.1 | 55.7 |
| SLidR | CVPR'22 | 36.6 | 48.1 | 39.8 | 52.1 | 44.2 | 56.3 |
| TriCC | CVPR'23 | 37.8 | 50.0 | 41.4 | 53.5 | 45.5 | 58.7 |
| CSC | CVPR'24 | 38.2 | 49.4 | 42.5 | 54.8 | 45.6 | 58.1 |
| ScaLR | CVPR'24 | 37.3 | 48.7 | 41.4 | 53.5 | 45.5 | 58.6 |
| LiMA | Ours | 39.4 | 50.1 | 43.2 | 55.3 | 46.0 | 59.5 |
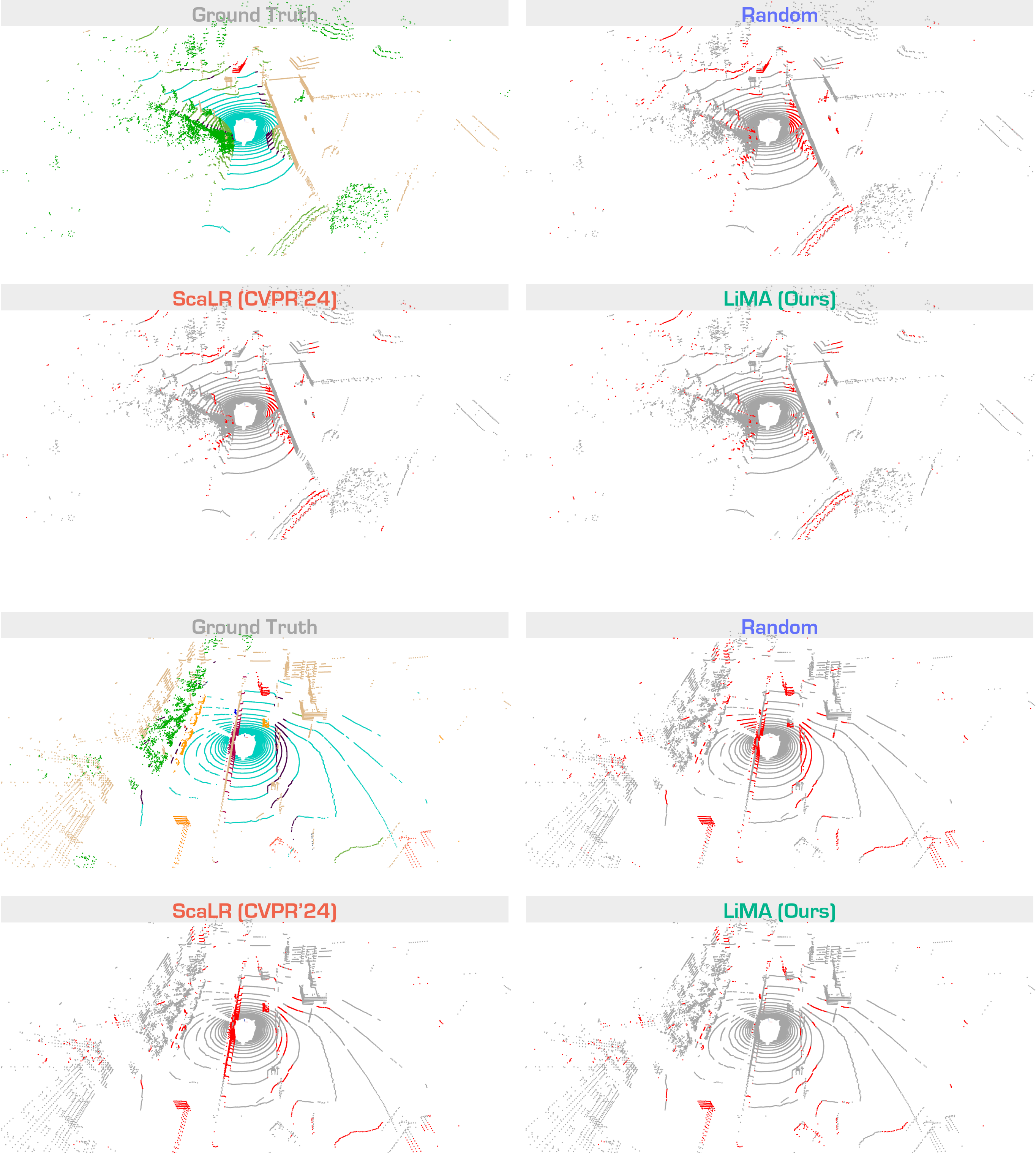 Figure 4. Qualitative assessments of state-of-the-art methods, pretrained on nuScenes and fine-tuned on nuScenes with 1% annotations.
The error maps depict correct and incorrect predictions in gray and red, respectively.
Best viewed in colors.
Figure 4. Qualitative assessments of state-of-the-art methods, pretrained on nuScenes and fine-tuned on nuScenes with 1% annotations.
The error maps depict correct and incorrect predictions in gray and red, respectively.
Best viewed in colors.
 Figure 5. Qualitative assessments of object detection, pretrained on nuScenes and fine-tuned on nuScenes with 5% annotations.
The groundtruth/predicted results are highlighted with blue/red boxes, respectively.
Best viewed in colors.
Figure 5. Qualitative assessments of object detection, pretrained on nuScenes and fine-tuned on nuScenes with 5% annotations.
The groundtruth/predicted results are highlighted with blue/red boxes, respectively.
Best viewed in colors.
@inproceedings{xu2025lima,
title = {Beyond One Shot, Beyond One Perspective: Cross-View and Long-Horizon Distillation for Better LiDAR Representations},
author = {Xu, Xiang and Kong, Lingdong and Wang, Song and Zhou, Chuanwei and Liu, Qingshan},
booktitle = {IEEE/CVF International Conference on Computer Vision},
year = {2025}
}