
2026
|
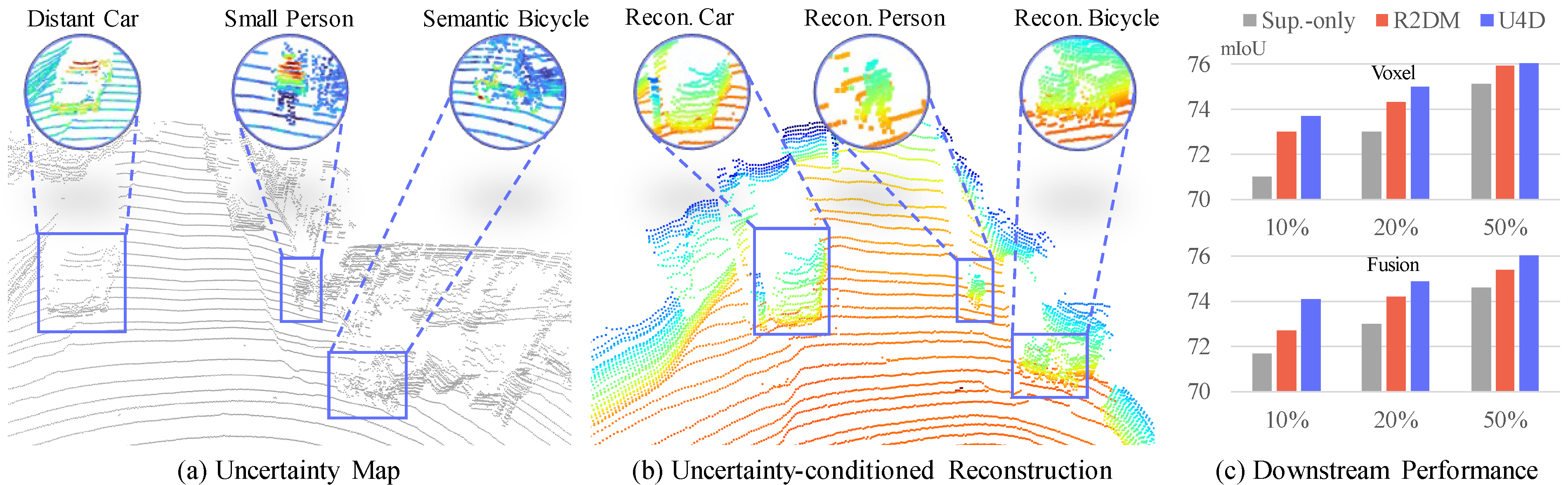
U4D: Uncertainty-Aware 4D World Modeling from LiDAR Sequences
IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2026 (Highlight)
|
|
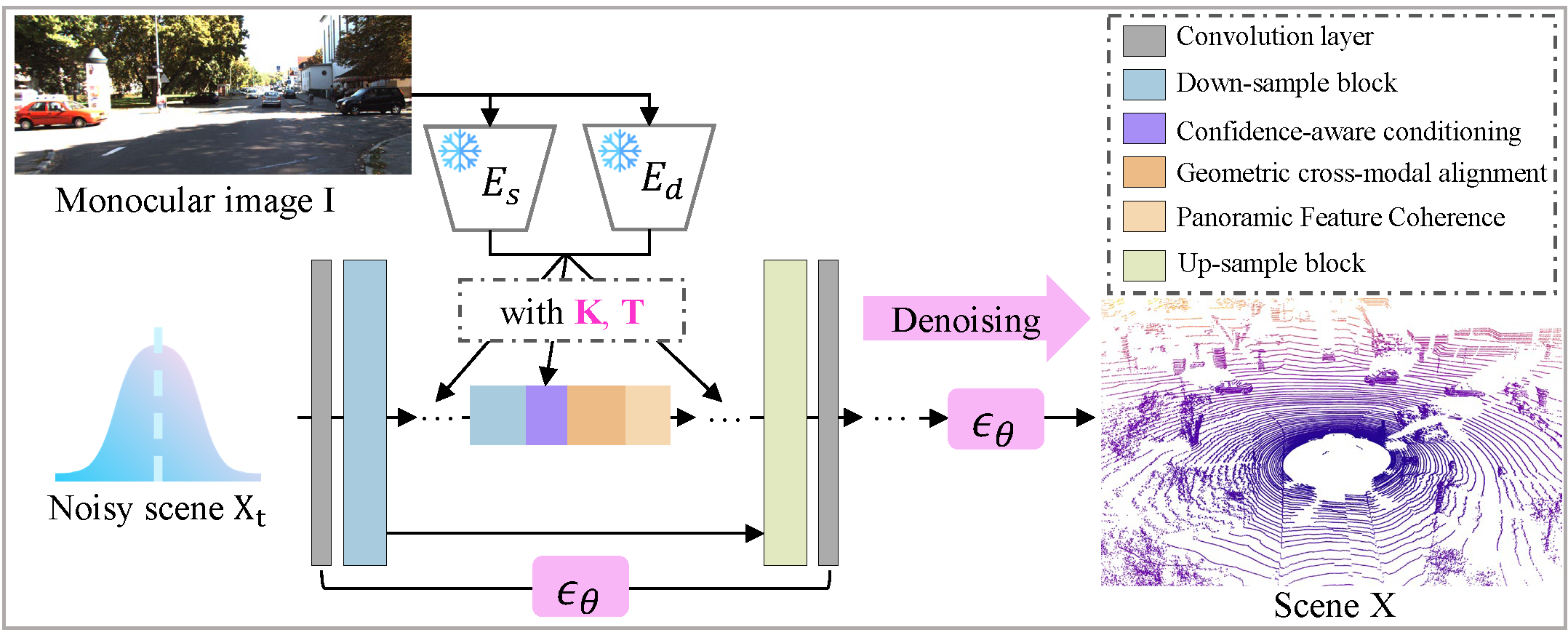
Veila: Panoramic LiDAR Generation from a Monocular RGB Image
IEEE International Conference on Robotics and Automation, 2026
|
|
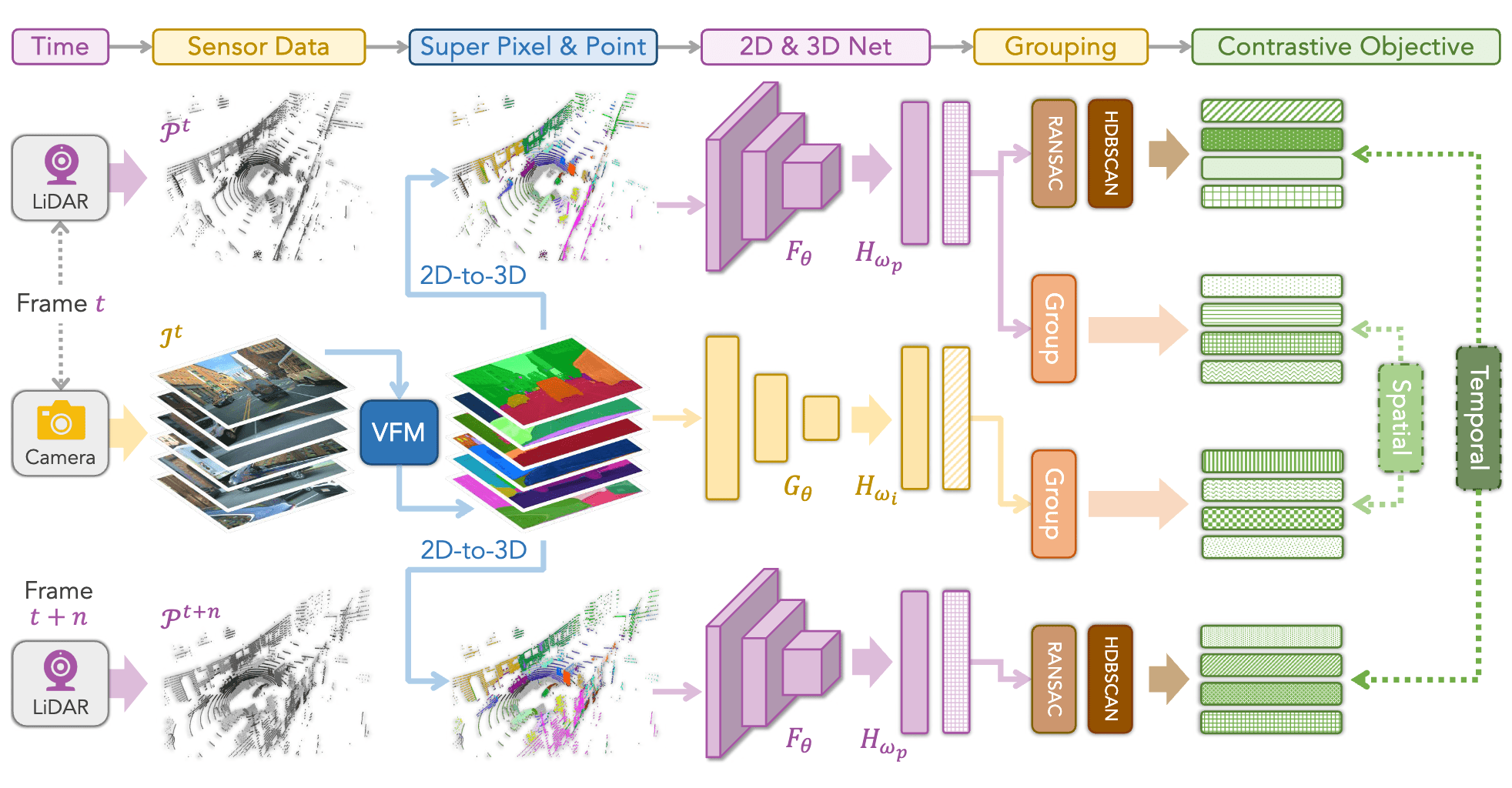
LargeAD: Large-Scale Cross-Sensor Data Pretraining for Autonomous Driving
IEEE Transactions on Pattern Analysis and Machine Intelligence, 2026
|
|
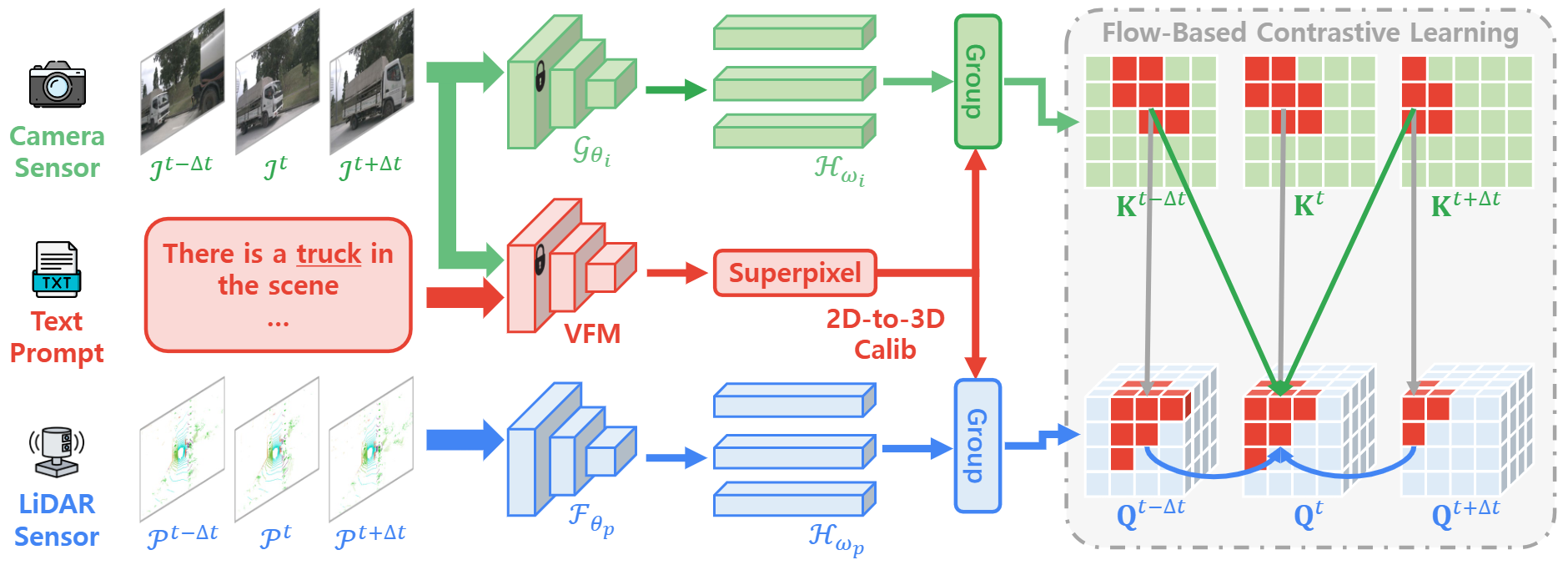
Enhanced Spatiotemporal Consistency for Image-to-LiDAR Data Pretraining
IEEE Transactions on Pattern Analysis and Machine Intelligence, 2026
|

|
OmniLiDAR: A Unified Diffusion Framework for Multi-Domain 3D LiDAR Generation
arXiv, 2026
|
2025
|
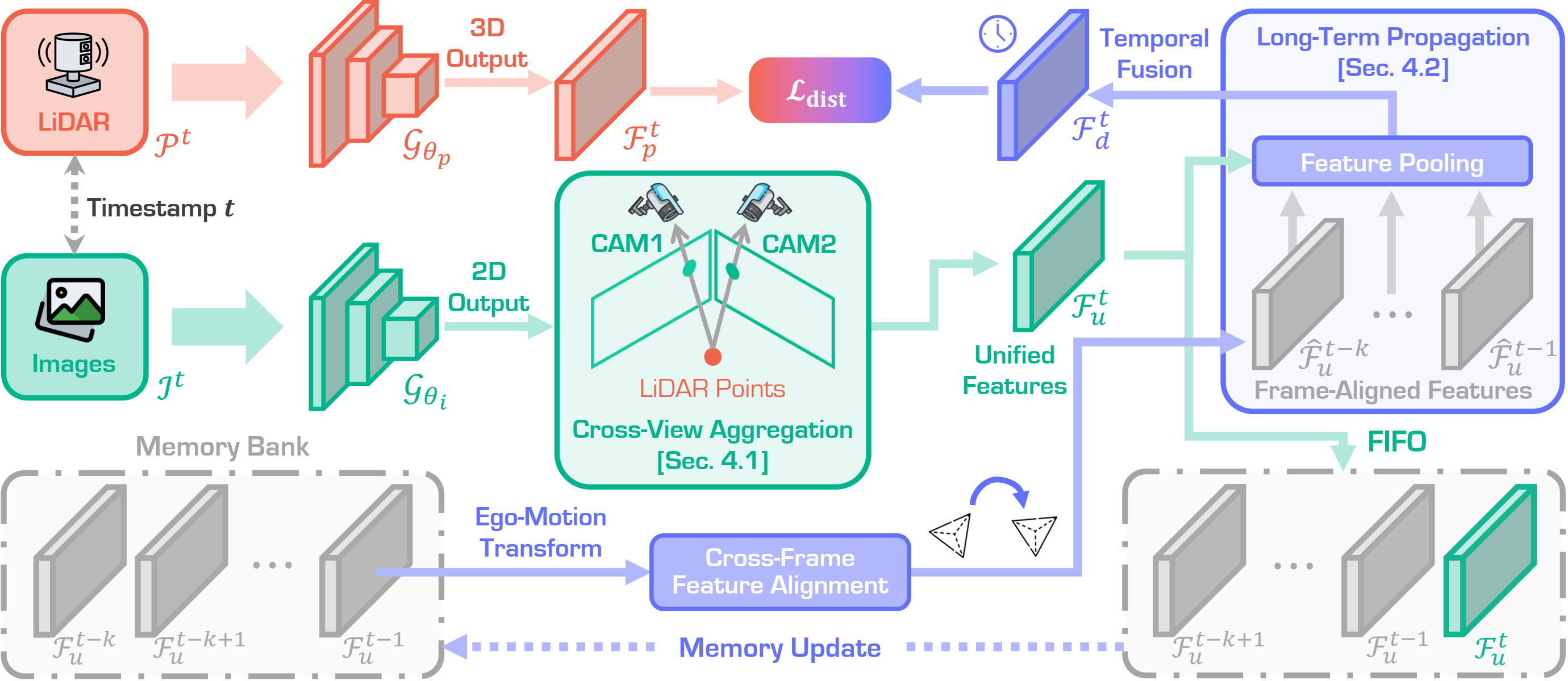
Beyond One Shot, Beyond One Perspective: Cross-View and Long-Horizon Distillation for Better LiDAR Representations
IEEE/CVF International Conference on Computer Vision, 2025
|
|
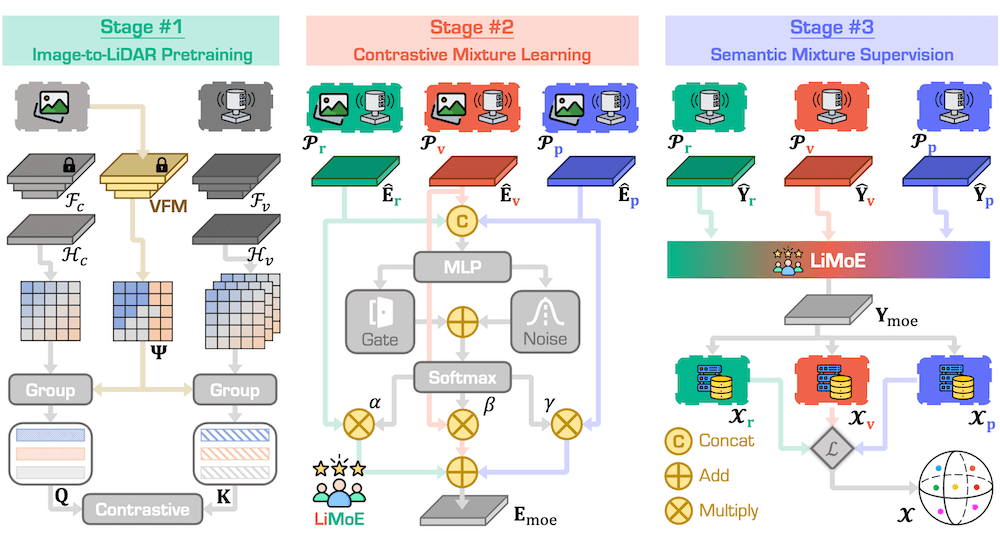
LiMoE: Mixture of LiDAR Representation Learners from Automotive Scenes
IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
|
|
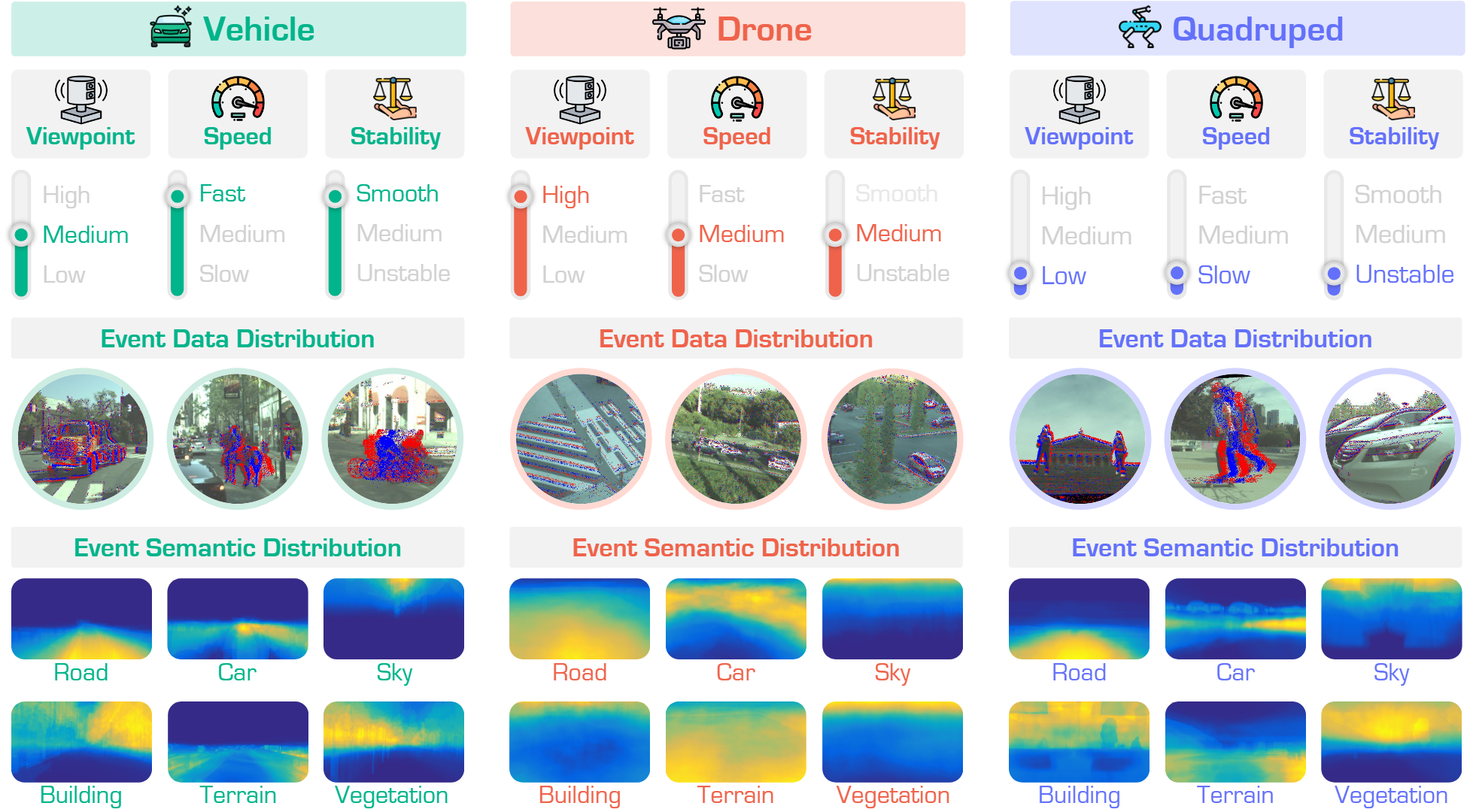
EventFly: Event Camera Perception from Ground to the Sky
IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
|
|
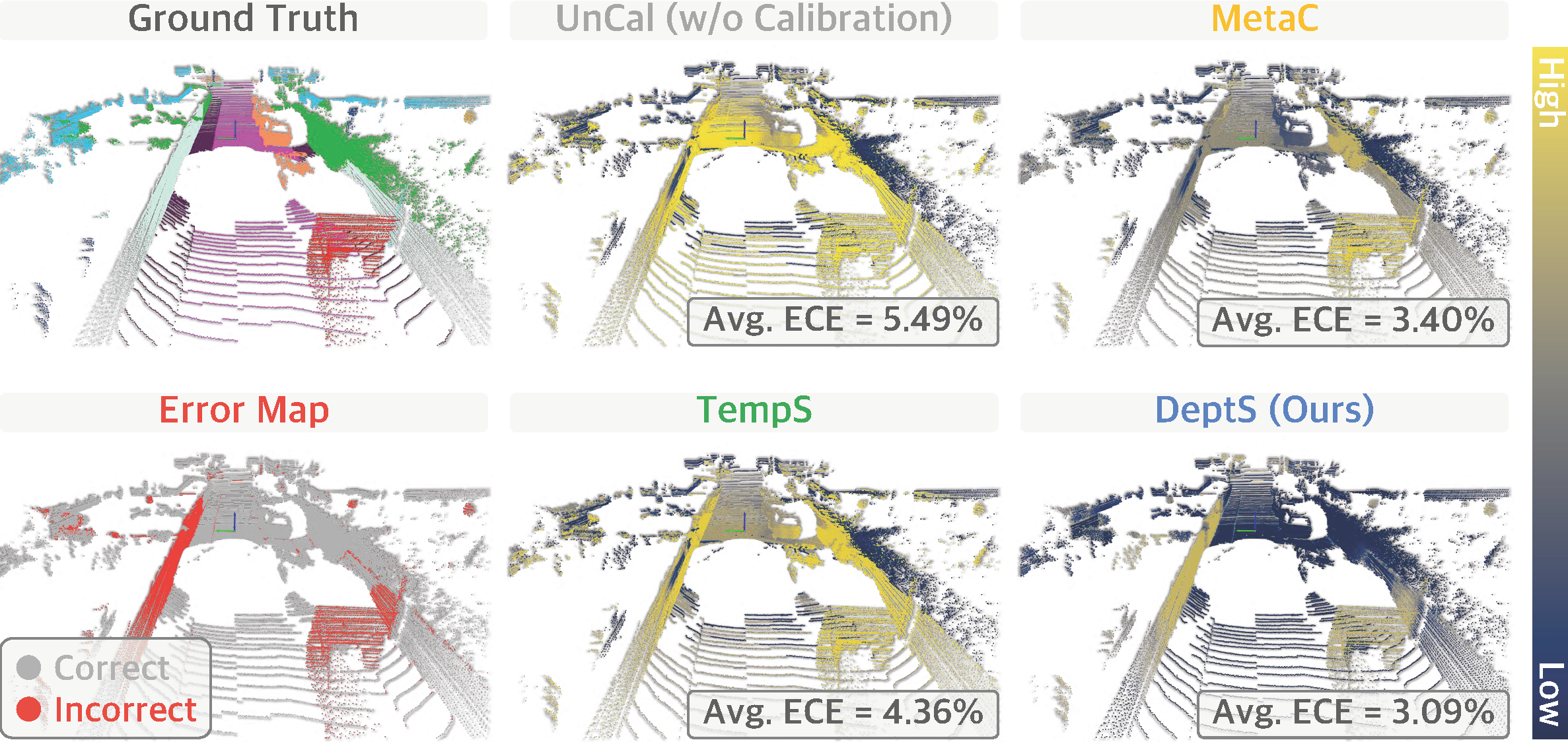
Calib3D: Calibrating Model Preferences for Reliable 3D Scene Understanding
IEEE/CVF Winter Conference on Applications of Computer Vision, 2025 (Oral Presentation)
|
|
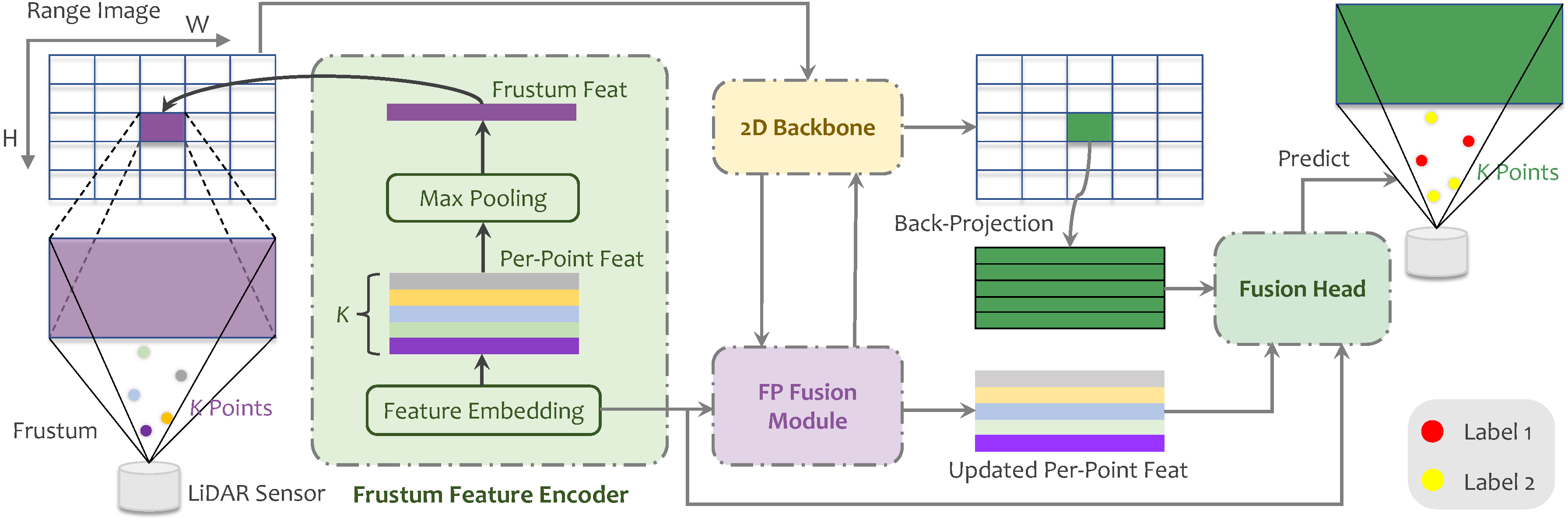
FRNet: Frustum-Range Networks for Scalable LiDAR Segmentation
IEEE Transactions on Image Processing, 2025
|
|
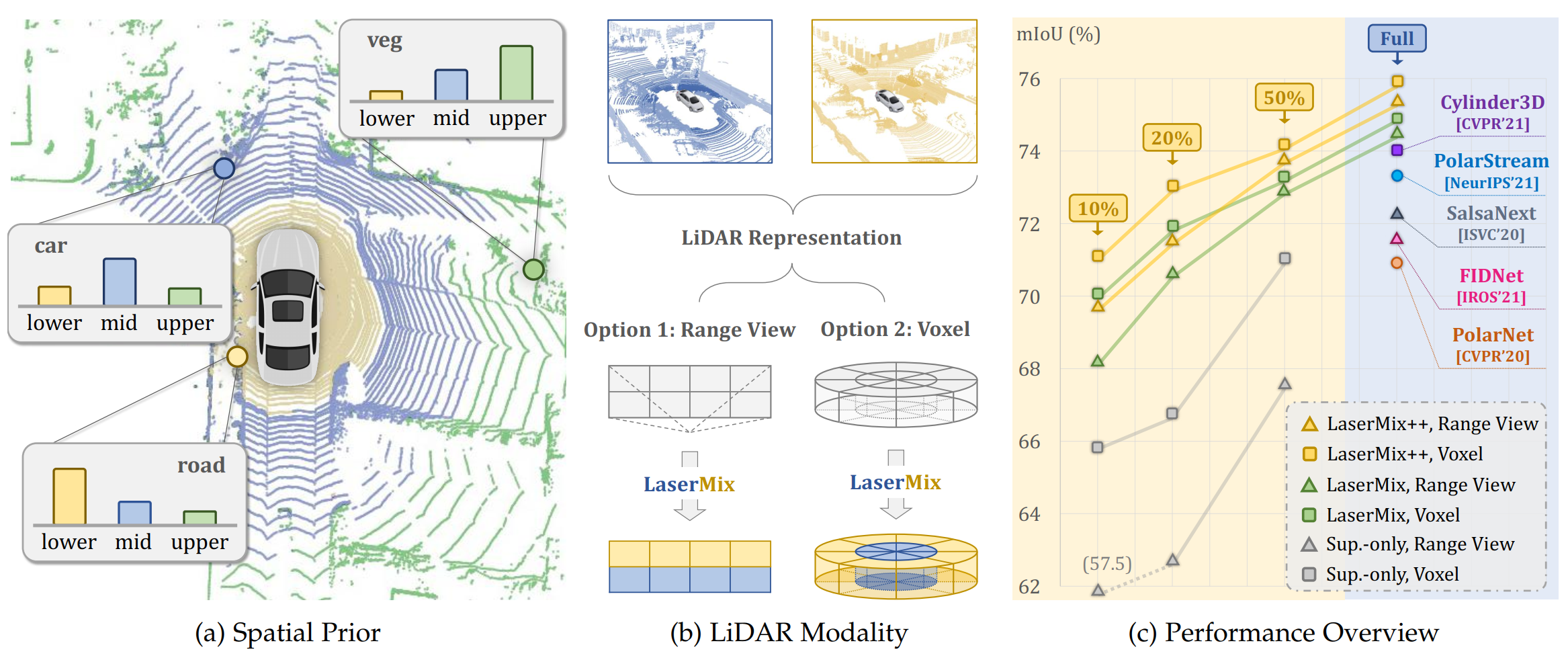
Multi-Modal Data-Efficient 3D Scene Understanding for Autonomous Driving
IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
|
2024
|
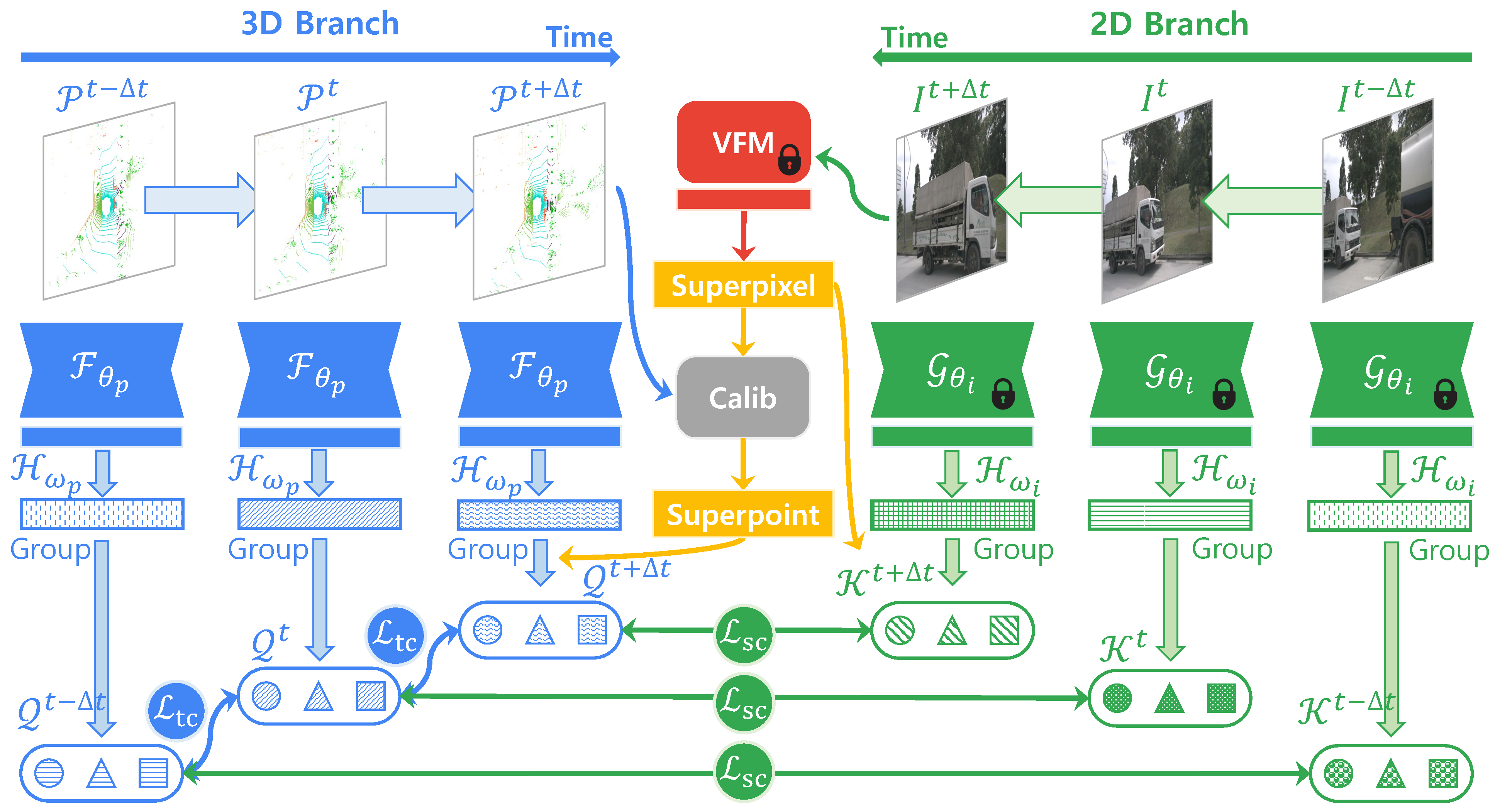
4D Contrastive Superflows are Dense 3D Representation Learners
European Conference on Computer Vision, 2024
|
|
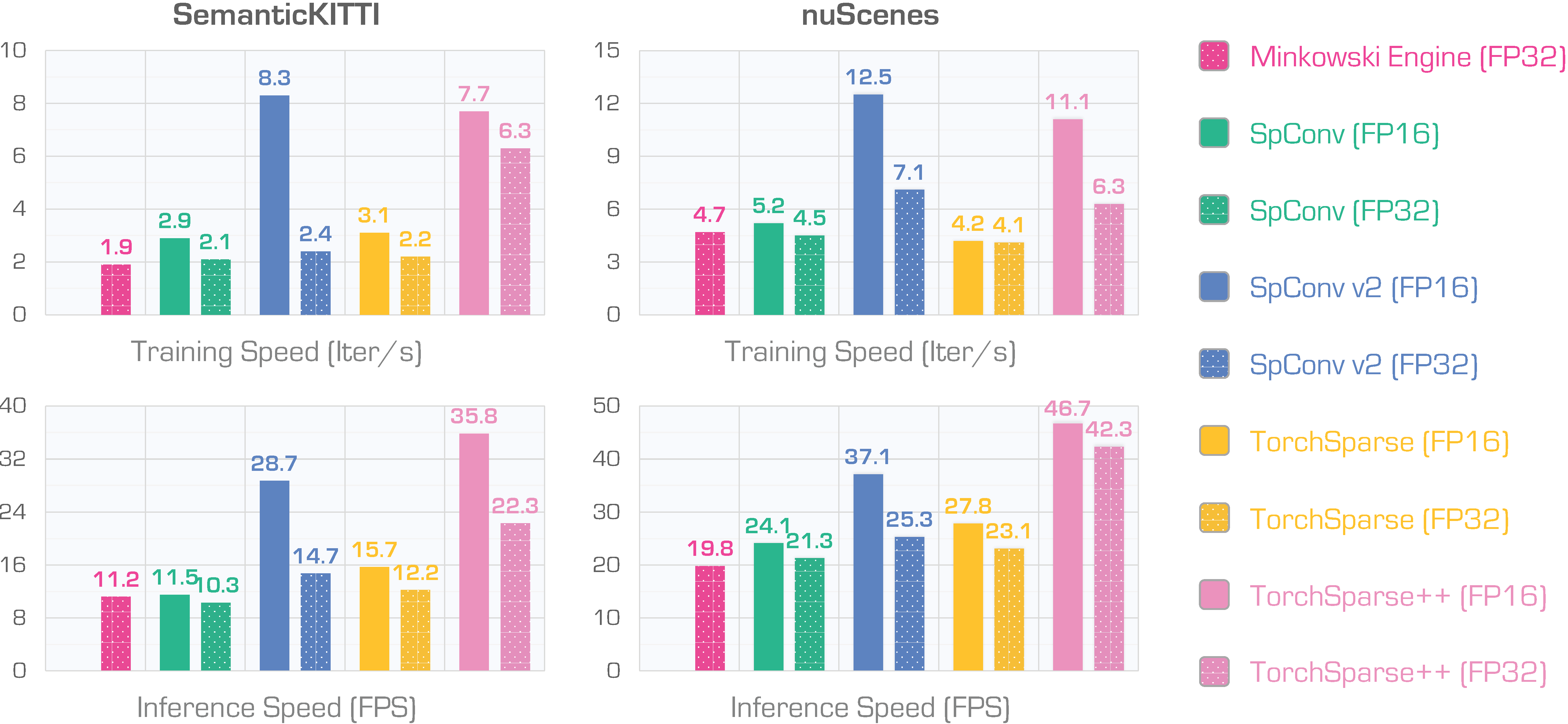
An Empirical Study of Training State-of-the-Art LiDAR Segmentation Models
arXiv, 2024
|
Before
|
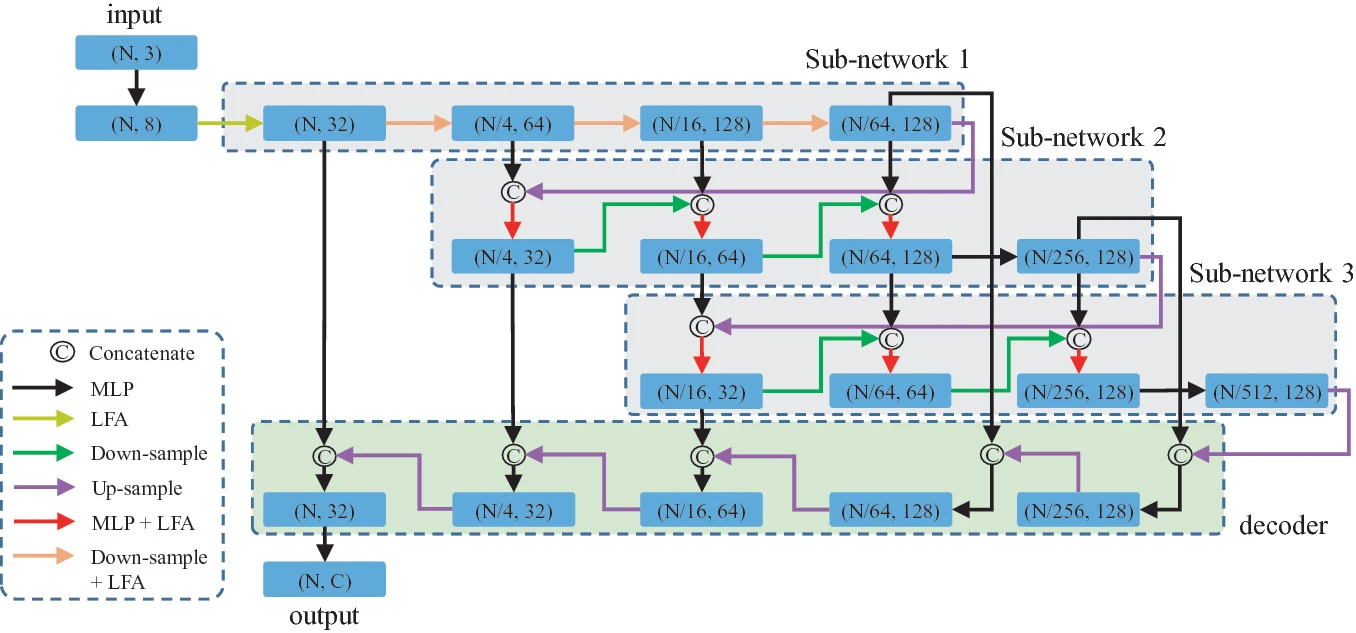
Waterfall-Net: Waterfall Feature Aggregation for Point Cloud Semantic Segmentation
Chinese Conference on Pattern Recognition and Computer Vision, 2022
|
|
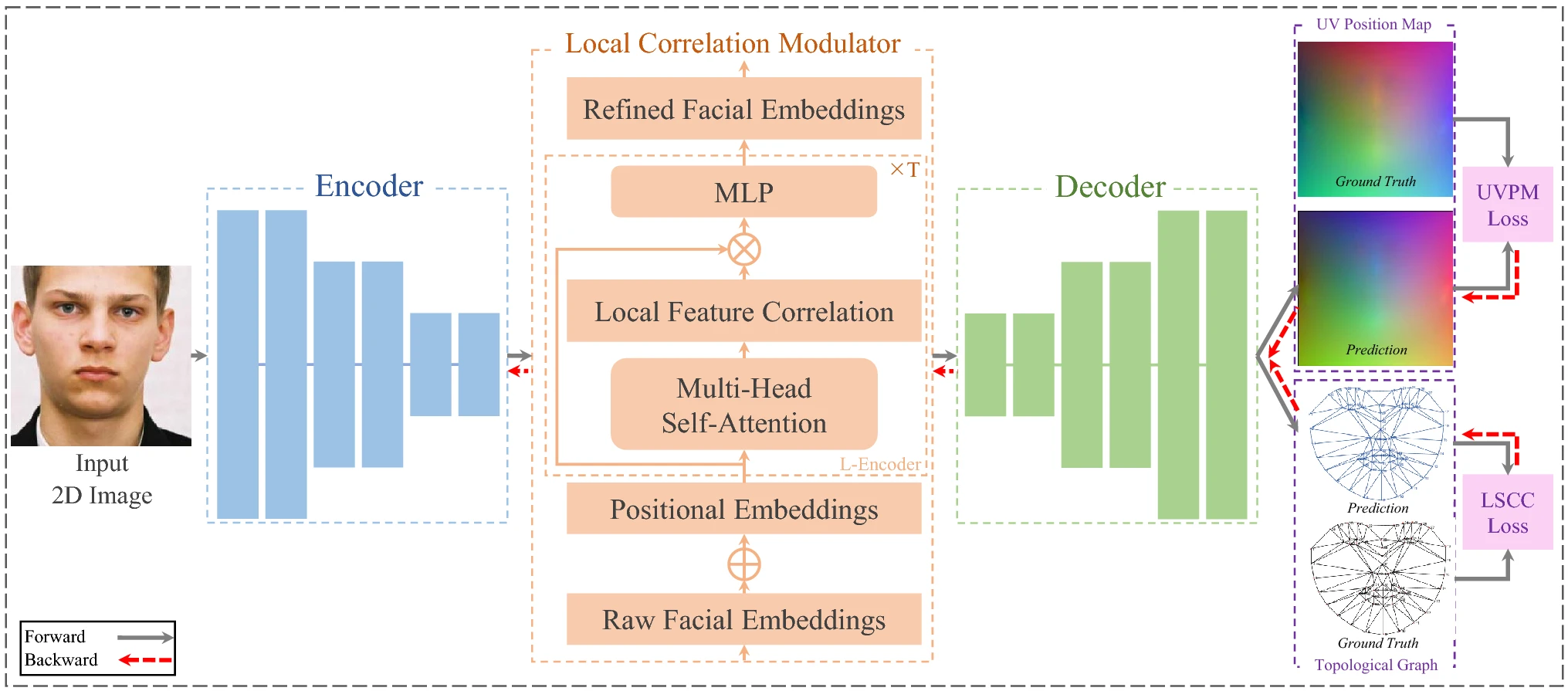
CED-Net: Contextual Encoder-Decoder Network for 3D Face Reconstruction
Multimedia Systems, 2022
|
|
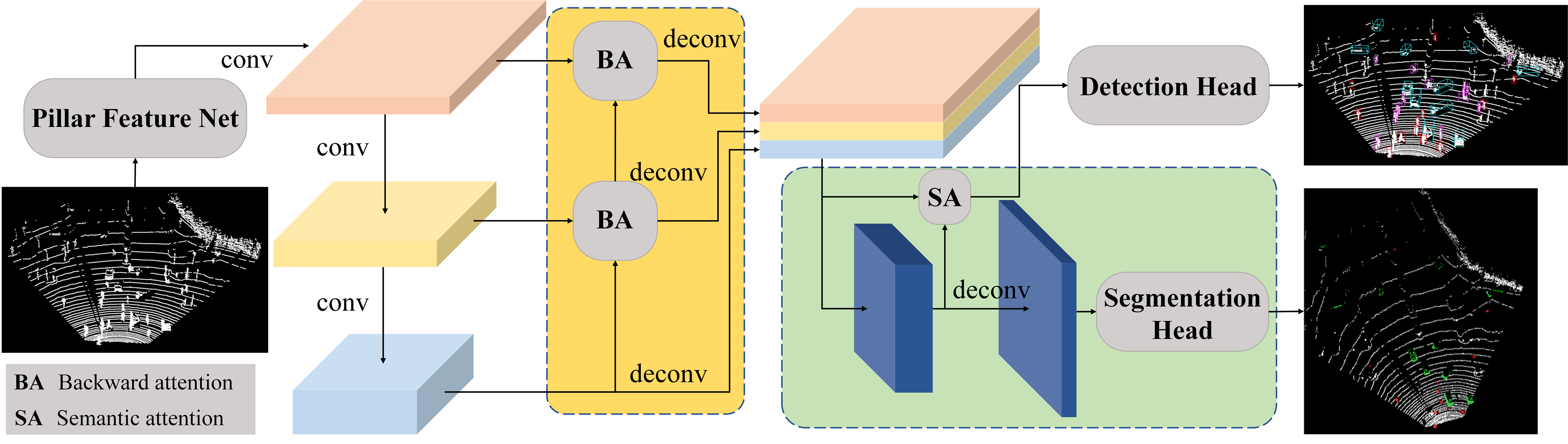
Semantic-Aware Object Detection for 3D Point Cloud
International Conference on Optics and Machine Vision, 2022
|
|
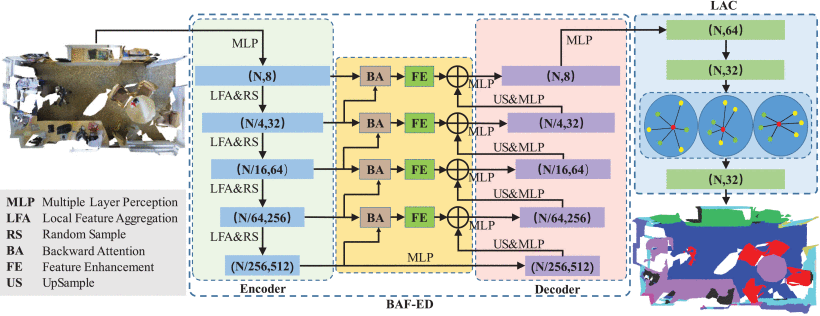
Backward Attentive Fusing Network with Local Aggregation Classifier for 3D Point Cloud Semantic Segmentation
IEEE Transactions on Image Processing, 2021
|